
Is This the End of Sora? Meta Introduces VideoJam AI Video Generator
VideoJAM is a new framework from Meta designed to make text-to-video generation models create more realistic motion.

Generating videos with complex, realistic movement remains one of the most elusive challenges for AI video models. Even the most popular tools like OpenAI’s Sora, Runway’s Gen-3, and Kling AI continue to struggle in maintaining motion coherence.
Try generating a scene of a person pouring milk or slicing a tomato, and you’ll likely notice inconsistencies—liquids defy gravity, objects merge into one another, and limbs twist unnaturally.
I tried to quickly generate a video of a boy biting on a burger using OpenAI’s Sora to demonstrate the problem.

You see what I mean? In the video, the boy is supposed to be eating the burger, but the burger appears to be floating in his hands, barely held, and when he supposedly takes a bite, nothing changes — the burger stays completely intact.
These imperfections stem from how current models focus on pixel-level reconstruction over motion fidelity during training. Video models often fail to recognize temporal relationships, resulting in static frames rather than a continuous, believable sequence of events.
Meta aims to solve this problem with a new framework called VideoJAM.
What is VideoJAM?
In simple terms, VideoJAM is a new framework from Meta designed to make text-to-video generation models create more realistic motion.
Current video models often struggle with motion, sometimes generating videos with unrealistic physics, even when the visual quality is high.
Examples of incoherent generations include basic motion like a person jogging (stepping on the same leg repeatedly) or complex motion like gymnastics.

When tasked with generating challenging motions like gymnastic elements, the generations often display severe deformations, such as the appearance of additional limbs.
In other cases, the generations exhibit behavior that contradicts fundamental physics, such as objects passing through other solid objects, like in the case of a hula hoop passing through the person below and rotational motion, failing to replicate simple repetitive patterns.

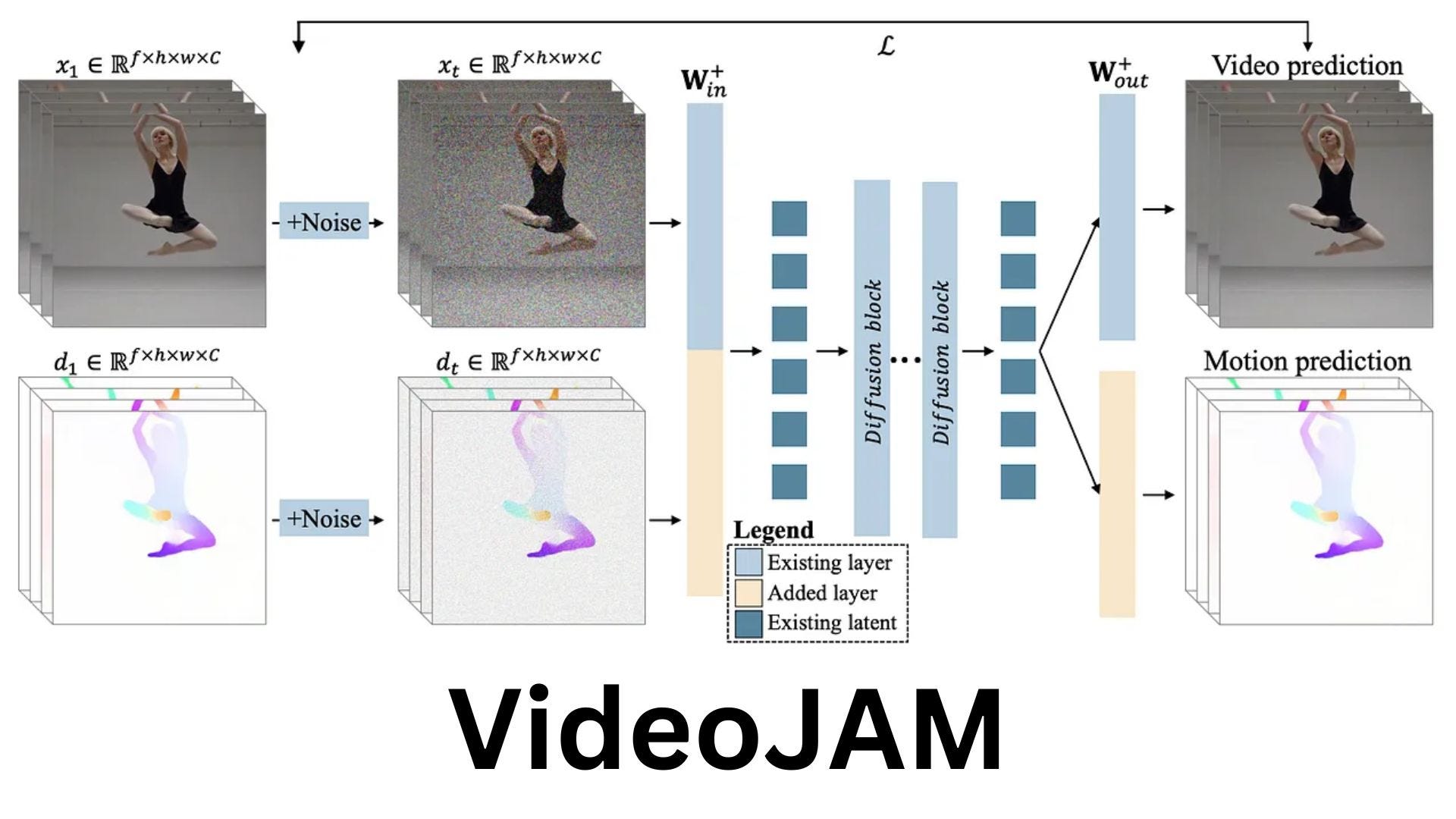
VideoJAM addresses these issues in two main ways:
Joint Appearance-Motion Representation: During training, VideoJAM teaches the model to understand both how things look (appearance) and how they move (motion) together. Instead of focusing solely on recreating the visual details, it also learns to predict the motion in video. This is achieved by modifying the video generation objective to predict both the generated pixels (appearance) and their corresponding motion from a single, learned representation.
Inner Guidance: During video generation, VideoJAM uses a technique called Inner Guidance. This helps the model to focus on creating coherent motion by using its own predictions about motion to guide the video generation process.
Check out the example below:
A slow-motion close-up of a chef slicing a tomato.

The tomato slicing is very impressive, with the way it reacts so convincingly as it’s being cut. Even the way the juices flow adds an extra touch of realism.
See more examples on this GitHub page.
The goal is to ensure that the generated videos display more realistic and coherent movement, even in complex scenarios. VideoJAM can be added to existing video models without needing to change the training data or make the model larger.
How Does VideoJAM Work?
The method involves two complementary phases:
Keep reading with a 7-day free trial
Subscribe to Generative AI Publication to keep reading this post and get 7 days of free access to the full post archives.