


OpenAI's New GPT-4o can Sing, Crack Jokes, and Respond in Real-Time
So is the sci-fi film "Her", already here?


Earlier today, thousands of AI enthusiasts eagerly tuned in to OpenAI’s highly anticipated livestream event, where the company unveiled its latest groundbreaking advancements in ChatGPT. While speculation ran rampant about the possibility of a revolutionary search feature to challenge Google’s dominance or the reveal of the much-awaited GPT-5 model, the actual announcement took a slightly different, but no less exciting, direction.
OpenAI introduced GPT-4o, a new model that’s smarter, cheaper, faster, better at coding, multi-modal, and mind-blowingly fast.

It was a smart move for OpenAI to demo the new features live at 1x speed instead of using a pre-recorded video (yes, I’m looking at you, Google).
So, what exactly is GPT-4o?
First things first, the “o” in GPT-4o stands for “omni,” representing the model’s multimodality support for both inputs and outputs.
GPT-4o can process and generate text, audio, and images in real time. It represents a significant step towards more natural human-computer interaction, accepting any combination of text, audio, and image inputs and generating corresponding outputs.
Perhaps the most notable advancement to GPT-4o is its almost real-time response as a voice assistant.
Perhaps the most notable advancement in GPT-4o is its almost real-time response as a voice assistant. It can respond to audio inputs in as little as 232 milliseconds on average, which is comparable to human response times in conversation.
This lightning-fast response time, combined with its ability to match the performance of GPT-4 Turbo on English text and code while showing significant improvements in non-English languages, makes GPT-4o a game-changer in the world of conversational AI.
And the best part? It’s notably faster and 50% cheaper in the API.
What’s new in GPT-4o?
Here is the list of new features in GPT-4o.
1. Real-time responses
When you chat with GPT-4o, it feels like talking to a real person. It can match your tone, crack jokes, and even sing in harmony.

This natural, speedy back-and-forth makes using the chatbot feel way more fun and engaging. But how did OpenAI pull this off?
Before GPT-4o, ChatGPT’s Voice Mode relied on a three-step process: audio was transcribed to text, then processed by GPT-3.5 or GPT-4, and finally converted back to audio. This led to slower response times (2.8 seconds for GPT-3.5 and 5.4 seconds for GPT-4) and loss of information like tone and background noise.
GPT-4o uses a single AI model trained to handle text, images, and audio all at once. This end-to-end processing allows GPT-4o to respond much faster and more naturally, picking up on nuances that previous models would miss.
2. Improved Reasoning
In addition to its impressive speed, GPT-4o has also achieved new heights in reasoning. It set a record score of 88.7% on the 0-shot COT MMLU benchmark, which tests general knowledge, and scored 87.2% on the traditional 5-shot no-CoT MMLU, another record.

However, it’s worth noting that other AI models like Llama3 400b are still in training and could potentially outperform GPT-4o in the future.
GPT-4o also demonstrated significant advancements in both mathematical reasoning and visual understanding.
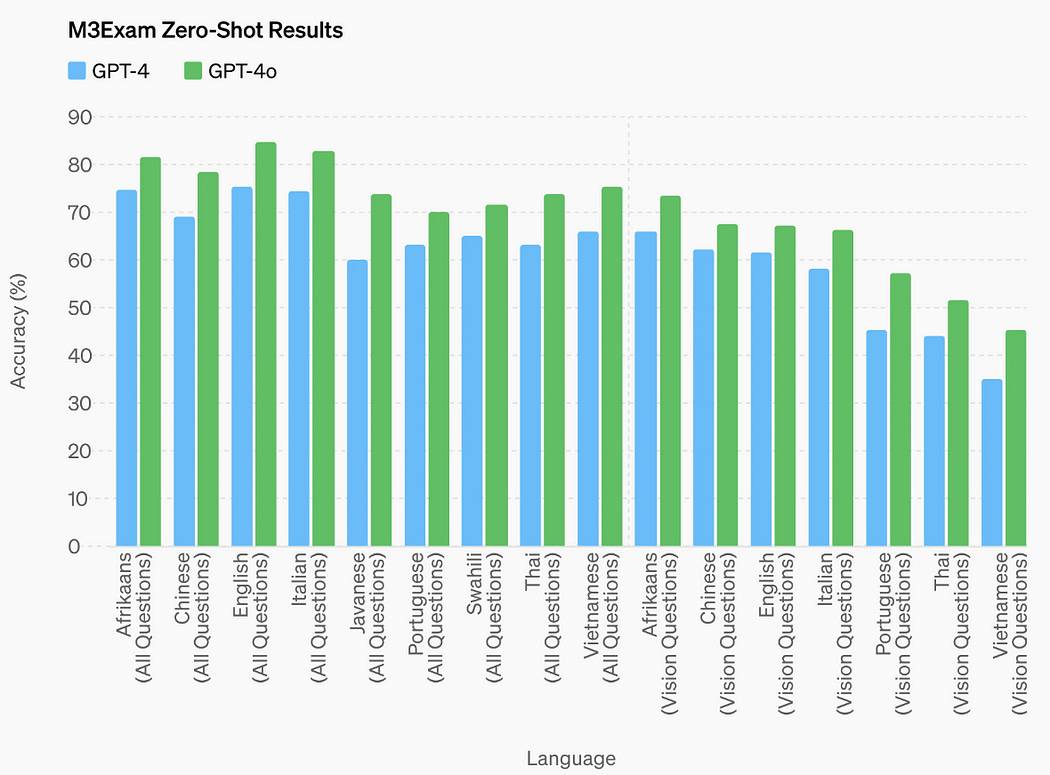
On the M3Exam benchmark, which evaluates performance on standardized test questions from various countries, often including diagrams and figures, GPT-4o outperformed GPT-4 across all languages tested.
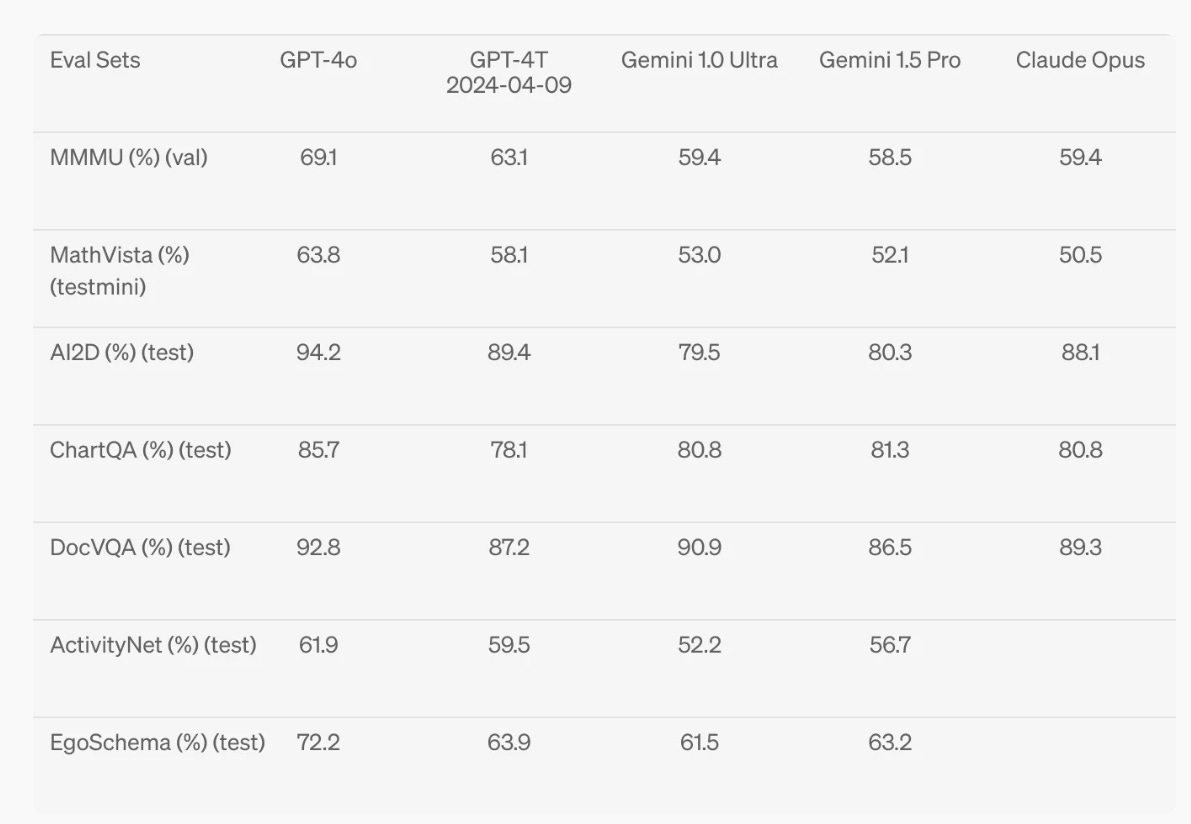
In terms of pure vision understanding, GPT-4o achieved state-of-the-art results on several key benchmarks, including MMMU, MathVista, and ChartQA, all in a 0-shot setting.
Head over to the announcement blog to explore some examples that showcase GPT-4o’s capabilities.
3. GPT-4o is free to use
Keep reading with a 7-day free trial
Subscribe to Generative AI Publication to keep reading this post and get 7 days of free access to the full post archives.